
الذكاء الاصطناعي
في عالم الذكاء الاصطناعي، تبرز النماذج اللغوية الكبيرة كواحدة من أبرز الابتكارات التقنية الحديثة، حيث أثبتت قدرتها على إنتاج نصوص معقدة وإبداعية، ومع ذلك، تظهر هذه النماذج ضعفا ملحوظا عندما يتعلق الأمر بحل المسائل الرياضية، مما يطرح تساؤلات حول حدود قدراتها.
لقد أحدثت النماذج اللغوية الكبيرة، مثل ChatGPT وGemini، ثورة في مجالات متعددة، بدءًا من التأليف الإبداعي وانتهاءً بتبسيط المعلومات المعقدة.
رغم ذلك، يُظهر الأداء الرياضي لهذه النماذج ضعفًا واضحًا، فعلى سبيل المثال، نجد أن نموذج Claude من شركة Anthropic لا يستطيع التعامل مع المسائل الكلامية، بينما نموذج Gemini من جوجل يواجه صعوبات في فهم المعادلات التربيعية، ويعاني نموذج Llama من ميتا من عدم القدرة على إجراء عمليات الجمع الأساسية.
يمكن أن يكون من المدهش أن نرى نماذج تتمتع بقدرة عالية على فهم النصوص والتعبير الإبداعي تعجز عن التعامل مع العمليات الحسابية البسيطة. لذلك، من المهم استكشاف الأسباب وراء هذا التناقض.
يُشير العديد من الخبراء إلى أن الفشل في حل المسائل الرياضية يعود إلى الطريقة التي تعالج بها هذه النماذج اللغة والرموز.
تستند النماذج اللغوية الكبيرة إلى عملية تُسمى "التجزئة" (Tokenization)، التي تتضمن تقسيم النص إلى وحدات أصغر تُعرف بالتوكنز.
هذه العملية، رغم أهميتها، تؤدي إلى فقدان بعض المعلومات الدقيقة، خاصة عندما يتعلق الأمر بالأرقام والعلاقات العددية، على سبيل المثال، قد يعامل النموذج الرقم 380 كرمز واحد، بينما يمثل الرقم 381 كزوج من الأرقام 38 و1، هذا يمكن أن يؤثر بشكل كبير على قدرة النموذج على إجراء العمليات الحسابية بدقة.
تعتمد النماذج على الإحصاء والاحتمالات للتنبؤ بالكلمات التالية في الجمل. تقوم بتحليل كميات ضخمة من البيانات النصية لتحديد الأنماط الإحصائية، مما قد يؤدي إلى أخطاء عند التعامل مع سياقات غير مألوفة أو طلبات استدلالية معقدة، فعلى سبيل المثال، إذا طُلب من ChatGPT ضرب عددين كبيرين مثل 57897 و12832، فإنه يعتمد على الأنماط التي تعلمها من البيانات التدريبية، مما يؤدي إلى نتائج خاطئة.
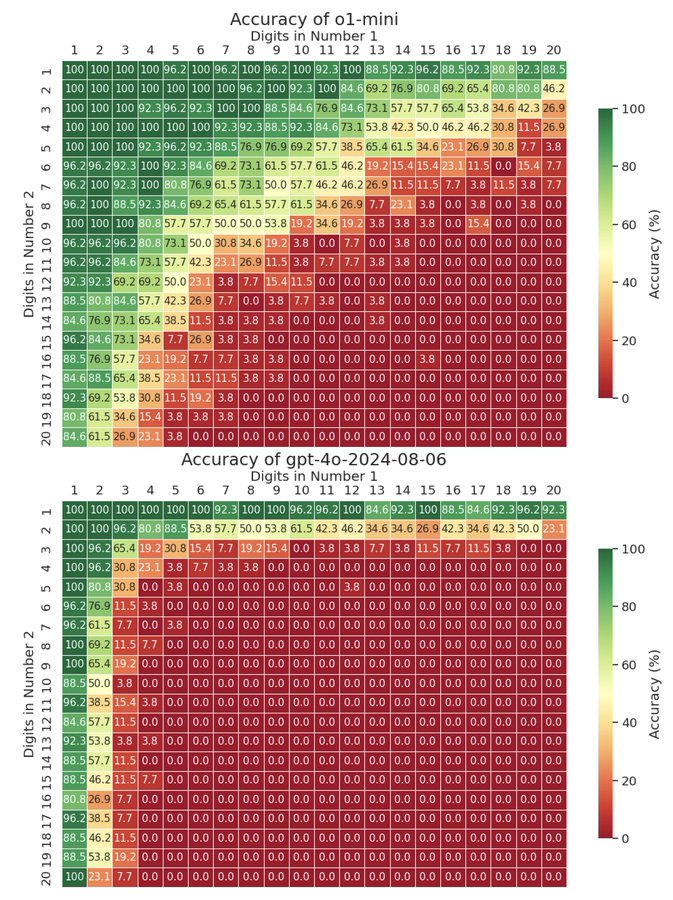
إحدى الدراسات التي أجراها يونتيان دينج، الأستاذ المساعد في جامعة واترلو، أظهرت أن النموذج المتقدم GPT-4o يُظهر دقة أقل من 30% في مسائل تتطلب إجراء عمليات ضرب تحتوي على أكثر من أربعة أرقام.
وأكد دينج أن الخطأ في أي خطوة وسيطة في العمليات الحسابية يمكن أن يتضاعف، مما يؤدي إلى نتائج غير صحيحة في النهاية.
المحتمل
يُطرح سؤال مهم هنا: إلى متى ستبقى الرياضيات تمثل تحديًا لهذه النماذج؟ تشير دراسة حديثة أجراها يونتيان دينج وفريقه إلى إمكانية تحسين أداء النماذج في مجال الرياضيات. على الرغم من أن نموذج GPT-4o واجه صعوبات، إلا أن نموذج o1 الجديد، الذي أُطلق في سبتمبر، أظهر نتائج واعدة، حيث تمكن من حل مسائل ضرب تتكون من تسعة أرقام بشكل صحيح في نصف الوقت.
يمثل هذا التطور علامة إيجابية على أن هذه النماذج يمكن أن تتعلم وتتحسن بمرور الوقت، مما يفتح الأبواب لإمكانيات جديدة في مجالات مثل التعليم والبحث العلمي.
ورغم التحديات المستمرة، يظل هناك أمل في أن تصبح النماذج مثل ChatGPT أكثر كفاءة في التعامل مع العمليات الرياضية، خاصة تلك التي تعتمد على خوارزميات واضحة.

السبت، 11 يونيو 2022 09:21 م

السبت، 11 يونيو 2022 09:35 م

الأحد، 12 يونيو 2022 12:53 م

الأحد، 12 يونيو 2022 03:03 م

الأحد، 12 يونيو 2022 03:33 م

الأحد، 12 يونيو 2022 04:09 م

الأحد، 12 يونيو 2022 04:40 م

الأحد، 12 يونيو 2022 05:05 م

الأحد، 12 يونيو 2022 06:58 م

الأحد، 12 يونيو 2022 07:59 م

الأحد، 12 يونيو 2022 08:24 م

الأحد، 12 يونيو 2022 11:25 م

الإثنين، 13 يونيو 2022 11:19 ص

الإثنين، 13 يونيو 2022 11:42 ص

الإثنين، 13 يونيو 2022 02:15 م

الإثنين، 13 يونيو 2022 03:08 م

الإثنين، 13 يونيو 2022 03:23 م

الإثنين، 13 يونيو 2022 04:08 م

الإثنين، 13 يونيو 2022 04:35 م

الإثنين، 13 يونيو 2022 05:00 م

الإثنين، 31 مارس 2025 09:58 ص

الأحد، 30 مارس 2025 01:14 م

الأحد، 30 مارس 2025 01:14 م

الأحد، 30 مارس 2025 01:14 م

الجمعة، 28 فبراير 2025 02:48 م

الإثنين، 24 فبراير 2025 09:37 ص

السبت، 22 فبراير 2025 12:40 م

الإثنين، 10 فبراير 2025 09:45 ص
ابحث عن مواصفات هاتفك
ماركات الموبايلات
أضغط هنا لمشاهدة كل الماركاتأحدث الموبايلات

Apple iPhone 13 Pro Max

Xiaomi Redmi Note 11

Samsung Galaxy A52s

OPPO Reno6 Pro 5G

realme GT2 Pro

vivo Y19

Honor 50 Pro

Huawei Nova 9

Nokia 8.3 5G
Back Top










